Casos y controles, desperdicio de plata o eficiencia?
El principal problema del estudio de casos y controles es que es que todos creen que es una porquería. Esa visión viene del diccionario de epidemiología de Miquel Porta. Donde se dice que se comparan casos de gente enferma con controles de gente no enferma.
Si yo estuviera a favor de esta simple definición, yo recomendaría JAMÁS hacer esta clase de diseño de estudio epidemiológicos, porque lógicamente esto es puro bullshit! Yo comí de este cuento! pero ahora que estudio epidemiología me doy cuenta de las bondades de este diseño de estudio, en especial en lugares de América (hablo de todo el continente americano, excepto Canadá), donde los registros son sumamente deficientes.
Incluso la wikipedia en inglés hablaba Bullshit, pero la última edición han corregido esos problemas
El estudio anidado!
Kenneth Rothman, un editor de la revista American Journal of Epidemiology, ha escrito varios libros, entre ellos, Epidemiología una introducción (lamentablemente, sólo está en inglés) donde se ha compilado evidencia de como realmente funcionan estos estudios y el valor de éstos.
Lo primero que hay que hacer para realizar un estudio de casos y controles es definir una cohorte. Es decir, debemos buscar:
- Una enfermedad (o bien una condición de importancia médica, como discapacidad, muerte, etc).
- Personas que sean suceptibles a sufrir la enfermedad.
- Un área geográfica donde vivan esas personas.
- Un tiempo (un tiempo en el cual van a colectar los casos).
Una vez que definimos una cohorte con esas 4 características, identificamos todos los casos (o la mayor parte de casos posible), y luego procedemos a identificar controles mediante uno de varios “esquemas” de muestro. Estos “esquemas” sirven para idealmente tomar una muestra al azar de TODA la población susceptible a desarrollar la enfermedad.
Los esquemas de muestreo de controles
Los esquemas de muestreo para colectar controles son:
- “Conjunto de riesgo”
- Controles sobrevivientes
- Controles de cohorte
- Controles “convenientes”
Esquema de muestreo de “Conjunto de riesgo” (“Risk set” en inglés)
Este esquema de muestreo es el estándar de oro. Es sumamente caro en América, pero es relativamente fácil de realizar en países de Europa de Norte. Para este esquema primero se identifican los casos, e inmediatamente (o poco tiempo después después), se identifica un control (o más dependiendo de cuántos controles por caso se decide antes de iniciar el estudio).
Se recomienda un máximo de 4 controles por caso. Sin embargo, este número va a depender del número de recursos disponibles para trabajar.
Es posible que un control, después de ser seleccionado, se convierta en caso. En esta circunstancia, ese individuo pertenece tanto a los casos como a los controles.
Esquema de sobrevivientes
Este esquema es particularmente útil en enfermedades infecciosas que causan la muerte o inmunidad después de estar enfermo. Se eligen controles al azar, después de acaba el periodo de estudio.
Esquema de cohortes
En este esquema, antes de iniciar el estudio, se eligen personas al azar.
Esquema de “conveniencia”
En este esquema se eligen amigos, personas hospitalizadas (con enfermedades que no estén relacionadas con la misma exposición de la enfermedad estudiada*), familiares, etc.
El mito la pared que divide la razón de riesgo de los odds ratios
Hay muchos videos en youtube que hablan de una “pared” que divide la razón de riesgo (Risk ratio) que se miden en las cohortes y los odds ratio. Según el maestro Rothman, esa pared NO EXISTE!
Primero vamos a ver un estudio de cohortes. Calculamos las incidencia (que es la proporción de casos nuevos en un tiempo determinado) en los expuestos y la dividimos entre los no expuestos:
- a-Casos expuestos
- b-Casos no expuestos
- C-Todos los expuestos

- D-Todos los no expuestos-

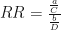

En el estudio de casos y controles, calculamos los “odds ratios”. Es algo parecido, pero a diferencia del RR en que los controles no necesariamente (aunque puede que sí) contienen a los casos.
- a-Casos expuestos
- b-Casos no expuestos
- c-Controles expuestos
- d-Controles no expuestos


Suponiendo que “a” y “b” sean lo suficientemente pequeños, entonces


Por consiguiente 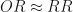
Aunque, los estudios de casos y controles NO pueden valorar la incidencia en expuestos y no expuestos, nos puede dar una idea bastante clara del valor del RR de la cohorte que le da origen, echando por tierra la mentira que 
Esto pone en su justo lugar a los estudios de casos y controles, en especial donde hay pocos recursos como Panamá al igual que el resto de América (excepto Canadá).


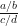 , tenemos que eso es igual a
, tenemos que eso es igual a  .
.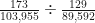 es lo mismo que
es lo mismo que 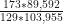 . El resultado, el IRR, es 1.16. Lo que nos indica en hay un 16% de probabilidades de que se denuncie un hecho delictivo en Herrera que en la provincia de Los Santos.
. El resultado, el IRR, es 1.16. Lo que nos indica en hay un 16% de probabilidades de que se denuncie un hecho delictivo en Herrera que en la provincia de Los Santos.
 .
.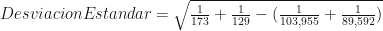 =0.116239… (mala idea redondear!).
=0.116239… (mala idea redondear!).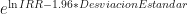 =0.92 (es decir que la población de Los Santos tiene un 8% más denuncias que Herrera.
=0.92 (es decir que la población de Los Santos tiene un 8% más denuncias que Herrera.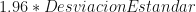 , el término se suma:
, el término se suma:  =1.45 (es decir que la población de Herrera tiene 45% más denuncias que Los Santos).
=1.45 (es decir que la población de Herrera tiene 45% más denuncias que Los Santos).